Scaling Event Sourcing for Netflix Downloads, Episode 1
Early in 2016, several Netflix teams were asked the question: “What would it take to allow members to download and view content offline on their mobile devices?”
For the Playback Licensing team, this meant that we needed to provide a content licensing system that would allow a member’s device to store and decrypt the downloaded content for offline viewing. To do this securely would require a new service to handle a complex set of yet-to-be defined business validations, along with a new API for client and server interactions. Further, we determined that this new service needed to be stateful, when all of our existing systems were stateless.
“Great! How long will that take you?”
In late November 2016, nine short months after that initial question was asked, Netflix successfully launched the new downloads feature that allows members to download and play content on their mobile devices. Several product and engineering teams collaborated to design and develop this new feature, which launched simultaneously to all Netflix members around the world.
This series of posts will outline why and how we built a new licensing system to support the Netflix downloads experience. In this first post of the series, we provide an overview of the Netflix downloads project and the changes it meant for the content licensing team at Netflix. Further posts will dive deeper into the solutions we created to meet these requirements.
How Streaming Playback Works
When a member streams content on Netflix, we deliver data to their device from our back-end servers before the member can commence playing the content. This data is retrieved via a complex device-to-server interaction on our Playback Services systems, which can be summarized as follows.
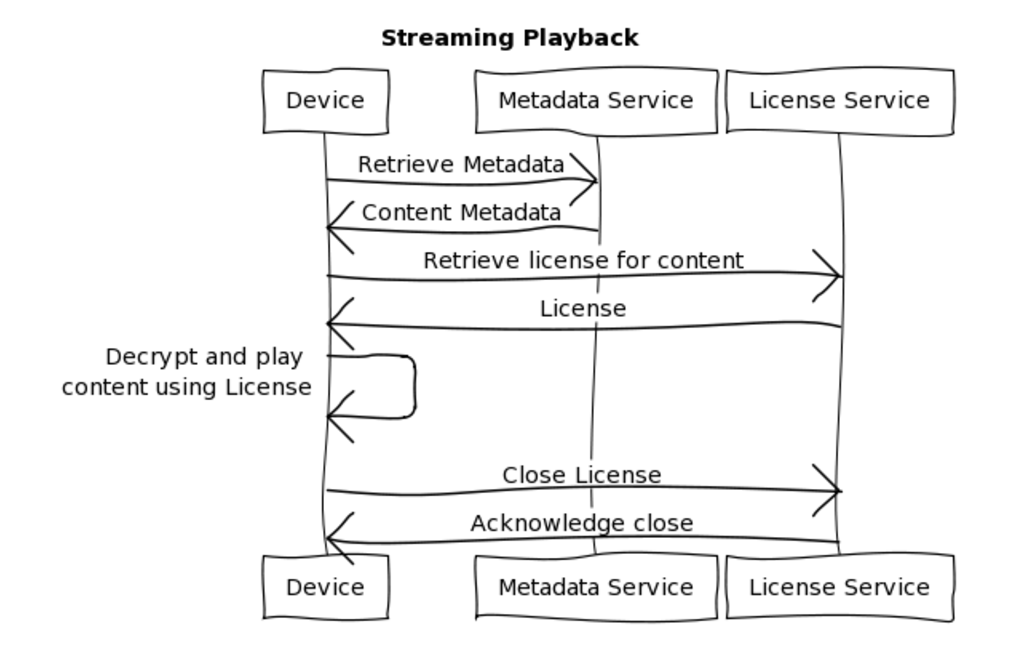
To play a title, the member’s device retrieves all the metadata associated with the content. The response object is known as the Playback Context, and includes data such as the image assets for the content and the URLs for streaming the content (see How Netflix Directs 1/3rd of Internet Traffic for an excellent overview of the streaming playback process and systems). The streamed data is encrypted with Digital Rights Management (DRM) technology and must be decrypted before it can be watched. This is done through the process of licensing, where a device can request a license for a particular title, and the license is then used to decrypt the content on that device. In the streaming case, the license is short-lived, and only able to be used once. When the member finishes watching the content, the license is considered consumed and no longer able to be used for playback.
Netflix supports several different DRM technologies to enable licensing for the content. Each of these live in their own microservice, requiring independent scaling and deployment tactics. This licensing tier needs to be as robust and reliable as possible; while many services at Netflix have fallbacks defined to serve a potentially degraded experience in the case of failures or request latency, the licensing services have no fallbacks possible. If licensing goes down, there is no playback. To reduce the risks to availability and resiliency, and to allow for flexible scaling, the licensing services have traditionally been stateless.
And Here Come Downloads…
The downloads flow differs slightly from the streaming one. Similar to the streaming flow, we generate a Playback Context (Metadata) for the downloaded content. Once we have the metadata for the content, we can start the license flow which is depicted as follows:
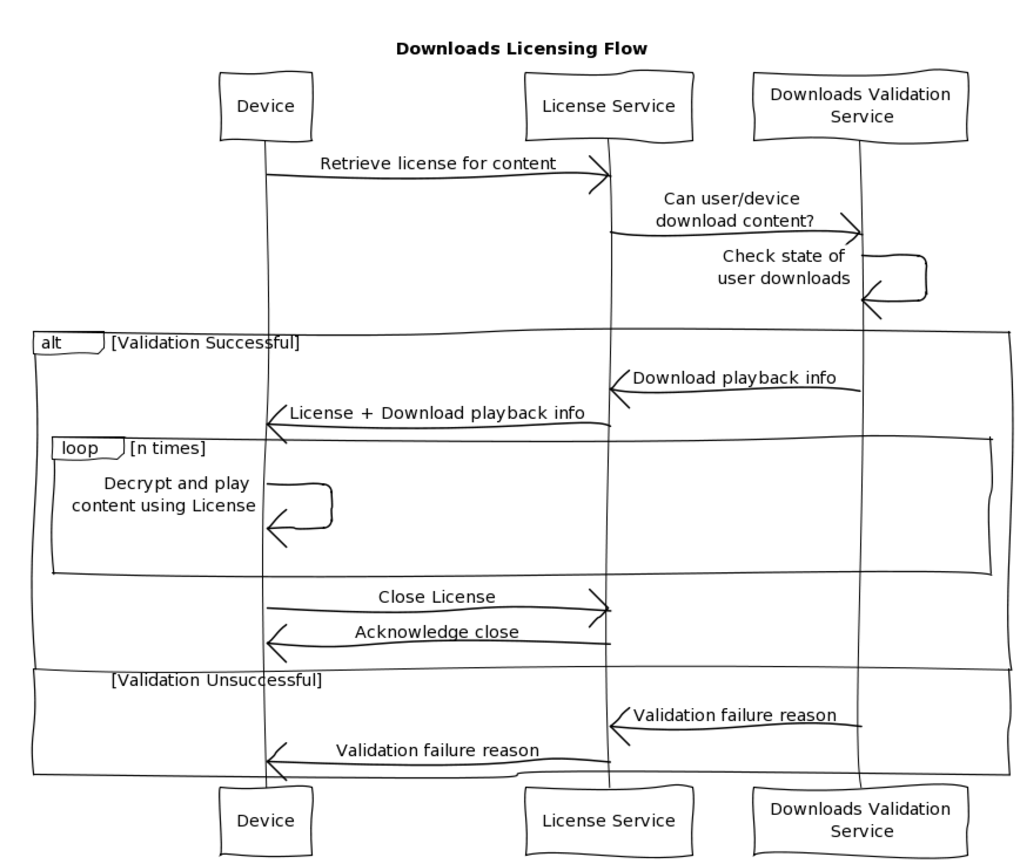
After checking to ensure a title is available for downloading, the member’s device attempts to acquire a license. We then perform several back-end checks to validate if the member is allowed to download the content. If the various business rules are satisfied, we return a license and any additional information used to play the content offline, and the device can then start downloading the encrypted bytes.
The license used for downloaded content is also different from streaming — it may be persisted on the device for a longer period of time, and can be reused over multiple playback sessions.
Once the title is downloaded to the device, it has a lifecycle as follows:
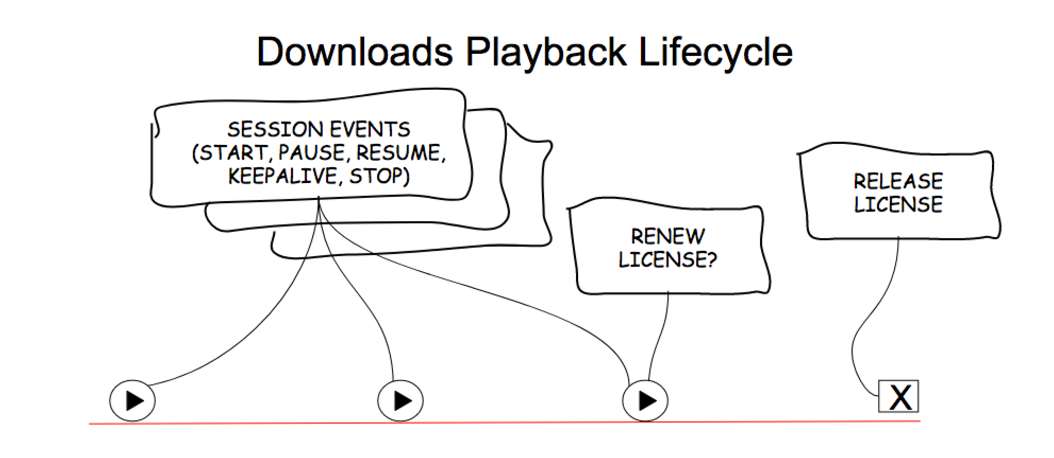
Every time a member presses play on the downloaded content, the application queues up session events to provide information on the viewing experience, and sends those up the next time the member goes online. After a defined duration for each title however, the original license retrieved with the downloaded content expires. At this point, depending on the content, it may be possible to renew the license, which requires the device to ask the back-end for a renewed license. This renewal is also validated against the business rules for downloads and, if successful, allows the content to continue to be played offline. Once the member deletes the content, the license is securely closed (released) which ensures the content can no longer be played offline.
A Maze of Restrictions
Netflix works with a variety of studio partners around the globe to obtain the best content for our members. The restrictions for downloaded content are generally more complex than for streaming, and far more varied amongst the studios. In addition to requirements related to how long a title can be watched, we have a variety of different caps based on the number of downloads for a device or per member, and potentially limitations on how many times the title can be downloaded or watched during a specified period of time.
We also have internal business restrictions related to download viewing, such as the number of devices on which content can be downloaded.
We must apply all of these restrictions across all the combined movies that a Netflix member downloads. Each time a member downloads a title or wants to extend the viewing time after the initial license expires, we must validate the request against all of the possible restrictions for the partner, taking into account the member’s past download interactions. If a member does not meet any of these requirements, the back-end sends back a response with the reason for why a download request failed.
Beginning of Downloads (and the end of this post)
With the introduction of the downloads feature, we needed to reconsider our approach to maintaining state. The downloads feature requires us to validate if a member should be allowed playback based on previous downloading history. We decided to perform this validation when the license was requested, so we needed a new stateful service that the licensing services could consult for validating business rules. We had a short period of time to design this new stateful system, which would enforce business rules and potentially reject licenses according to a yet-to-be defined set of requirements.
We had an amazing opportunity to create a new service from scratch, with an existing user base of millions, and a limited time to create it in. Exciting times lay ahead!
More, Please!
In the next post of this series, we will discuss the service we created to validate and track downloads usage: an Event-Sourced backed stateful storage microservice. Future posts will deep-dive into the implementation details, including the use of data versioning and snapshotting to provide flexibility and scale.
The team recently presented this topic at QCon New York and you can download the slides and watch the video here. Join us at Velocity New York (October 2–4, 2017) for an even more technical deep dive on the implementation and lessons learned.
The authors are members of the Netflix Playback Licensing team. We pride ourselves on being experts at distributed systems development and operations. And, we’re hiring Senior Software Engineers! Email kcasella@netflix.com or connect on LinkedIn if you are interested.