In this post, I’m going to answer one simple question: How does a GraphQL server turn a query into a response?
If you’re new to GraphQL, get the three minute intro in How do I GraphQL? before reading on. That way you’ll get more out of reading this post.
Here’s the ground we’ll cover in this post:
- GraphQL queries
- Schema and resolve functions
- GraphQL execution — step by step
Ready? Let’s jump right in!
GraphQL Queries
GraphQL queries have a very simple structure and are easy to understand. Take this one:
{
subscribers(publication: "apollo-stack"){
name
email
}
}
It doesn’t take a rocket scientist to figure out that this query would return the names and e-mails of all subscribers of our publication, Building Apollo, if we built an API for it. Here’s what the response would look like:
{
subscribers: [
{ name: "Jane Doe", email: "jane@doe.com" },
{ name: "John Doe", email: "john@doe.com" },
...
]
}
Notice how the shape of the response is almost the same as that of the query. The client-side of GraphQL is so easy, it’s practically self-explanatory!
But how about the server? Is it more complicated?
It turns out that GraphQL servers are quite simple, too. After reading this post, you’ll know exactly what’s going on inside a GraphQL server, and you’ll be ready to build your own.
Schema and Resolve Functions
Every GraphQL server has two core parts that determine how it works: a schema and resolve functions.
The schema: The schema is a model of the data that can be fetched through the GraphQL server. It defines what queries clients are allowed to make, what types of data can be fetched from the server, and what the relationships between these types are. For example:

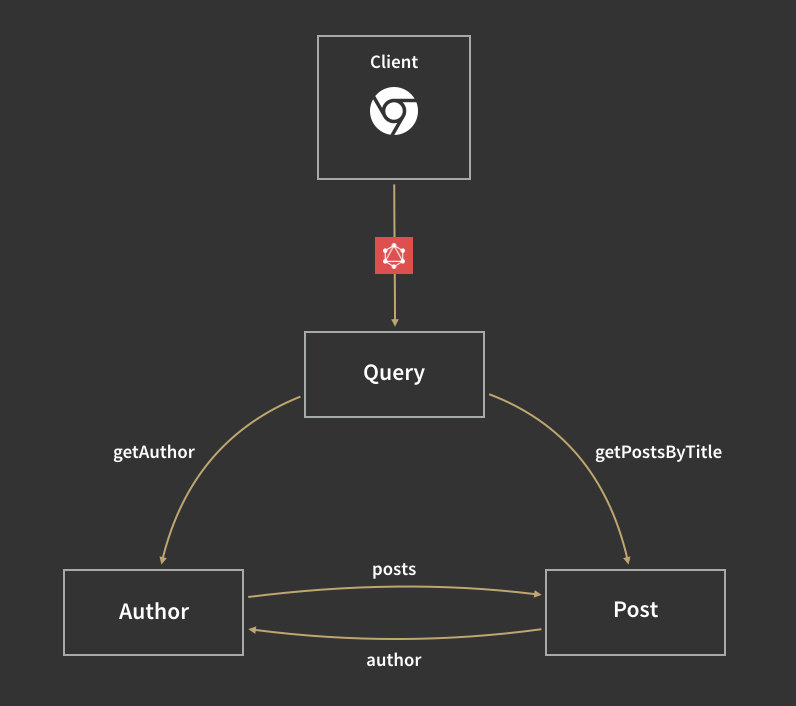
In GraphQL schema notation, it looks like this:
type Author { id: Int name: String posts: [Post] }type Post { id: Int title: String text: String author: Author }type Query { getAuthor(id: Int): Author getPostsByTitle(titleContains: String): [Post] }schema { query: Query }
This schema is quite simple: it states that the application has three types — Author, Post and Query. The third type— Query — is just there to mark the entry point into the schema. Every query has to start with one of its fields: getAuthor or getPostsByTitle. You can think of them sort of like REST endpoints, except more powerful.
Author and Post reference each other. You can get from Author to Post through the Author’s “posts” field, and you can get from Post to Author through the Posts’ “author” field.
The schema tells the server what queries clients are allowed to make, and how different types are related, but there is one critical piece of information that it doesn’t contain: where the data for each type comes from!
That’s what resolve functions are for.
Resolve Functions
Resolve functions are like little routers. They specify how the types and fields in the schema are connected to various backends, answering the questions “How do I get the data for Authors?” and “Which backend do I need to call with what arguments to get the data for Posts?”.
GraphQL resolve functions can contain arbitrary code, which means a GraphQL server can to talk to any kind of backend, even other GraphQL servers. For example, the Author type could be stored in a SQL database, while Posts are stored in MongoDB, or even handled by a microservice.
Perhaps the greatest feature of GraphQL is that it hides all of the backend complexity from clients. No matter how many backends your app uses, all the client will see is a single GraphQL endpoint with a simple, self-documenting API for your application.
Here’s an example of two resolve functions:
getAuthor(_, args){ return sql.raw('SELECT * FROM authors WHERE id = %s', args.id); }posts(author){ return request(`https://api.blog.io/by_author/${author.id}`); }
Of course, you wouldn’t write the query or url directly in a resolve function, you’d put it in a separate module. But you get the picture.
Query execution — step by step
Alright, now that you know about schema and resolve functions, let’s look at the execution of an actual query.
Side note: The code below is for GraphQL-JS, the JavaScript reference implementation of GraphQL, but the execution model is the same in all GraphQL servers I know of.
At the end of this section, you’ll understand how a GraphQL server uses the schema and resolve functions together to execute the query and produce the desired result.
Here’s a query that works with the schema introduced earlier. It fetches an author’s name, all the posts for that author, and the name of the author of each post.
{
getAuthor(id: 5){
name
posts {
title
author {
name # this will be the same as the name above
}
}
}
}
Side note: If you look closely, you will notice that this query fetches the name of the same author twice. I’m just doing that here to illustrate GraphQL while keeping the schema as simple as possible.
Here are the three high-level steps the server takes to respond to the query:
- Parse
- Validate
- Execute
Step 1: Parsing the query
First, the server parses the string and turns it into an AST — an abstract syntax tree. If there are any syntax errors, the server will stop execution and return the syntax error to the client.
Step 2: Validation
A query can be syntactically correct, but still make no sense, just like the following English sentence is syntactically correct, but doesn’t make any sense: “The sand left through the idea”.
The validation stage makes sure that the query is valid given the schema before execution starts. It checks things like:
- is getAuthor a field of the Query type?
- does getAuthor accept an argument named id?
- Are name and posts fields on the type returned by getAuthor?
- … and many more …
As an application developer, you don’t need to worry about this part, because the GraphQL server does it automatically. Put that in contrast to most RESTful APIs, where it’s up to you — the developer — to make sure that all the parameters are valid.
Step 3: Execution
If validation is passed, the GraphQL server will execute the query.
Every GraphQL query has the shape of a tree — i.e. it is never circular. Execution begins at the root of the query. First, the executor calls the resolve function of the fields at the top level — in this case just getAuthor — with the provided parameters. It waits until all these resolve functions have returned a value, and then proceeds in a cascading fashion down the tree. If a resolve function returns a promise, the executor will wait until that promise is resolved.
That was the one-paragraph description of the execution flow. I think it’s always easier to understand things when they’re illustrated in different ways, so I made a diagram, a table and even a video that walks you through it step by step.
The execution flow in diagram form:

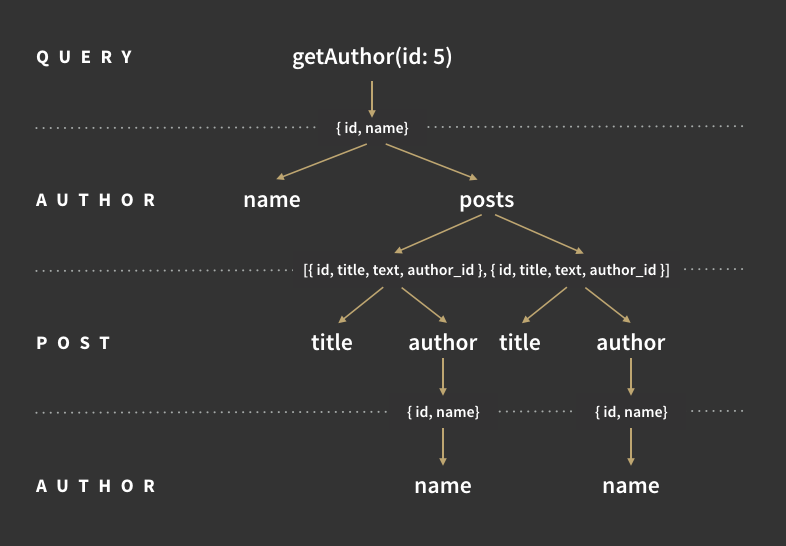
The execution flow in table form:
3.1: run Query.getAuthor
3.2: run Author.name and Author.posts (for Author returned in 3.1)
3.3: run Post.title and Post.author (for each Post returned in 3.2)
3.4: run Author.name (for each Author returned in 3.3)
The execution flow in text form (with all the details):
Feel free to skip this section if you already understand how it works from the diagram or the table.
Just for convenience, here’s the query again:
{
getAuthor(id: 5){
name
posts {
title
author {
name # this will be the same as the name above
}
}
}
}
In this query, there is only one root field — getAuthor — and there is one parameter — id — with value 5. The getAuthor resolve function will run and return a promise.
getAuthor(_, { id }){ return DB.Authors.findOne(id); }// let's assume this returns a promise that then resolves to the // following object from the database: { id: 5, name: "John Doe" }
The promise is resolved when the database call returns. As soon as that happens, the GraphQL server will take the return value of this resolve function — an object in this case — and pass it to the resolve functions of the name and posts fields on Author, because those are the fields that were requested in the query. The name and posts resolve functions run in parallel:
name(author){ return author.name; }posts(author){ return DB.Posts.getByAuthorId(author.id); }
The name resolve function is pretty straightforward: it simply returns the name property of the author object that was just passed down from the getAuthor resolve function.
The posts resolve function makes a call to the database and returns a list of post objects:
// list returned by DB.Posts.getByAuthorId(5)
[{
id: 1,
title: "Hello World",
text: "I am here",
author_id: 5
},{
id: 2,
title: "Why am I still up at midnight writing this post?",
text: "GraphQL's query language is incredibly easy to ...",
author_id: 5
}]
Note: GraphQL-JS waits for all promises in a list to be resolved/rejected before it calls the next level of resolve functions.
Because the query asks for the title and author fields of each Post, GraphQL then runs four resolve functions in parallel: the title and author for each post.
The title resolve function is trivial again, and the author resolve function is the same as the one for getAuthor, except that it uses the author_id field on post, whereas the getAuthor function used the id argument:
author(post){
return DB.Authors.findOne(post.author_id);
}
Finally, the GraphQL executor calls the name resolve function of Author again, this time with the author objects returned by the author resolve function of Posts. It runs twice — once for each Post.
And we’re done! All that’s left to do is pass the results up to the root of the query and return the result:
{
data: {
getAuthor: {
name: "John Doe",
posts: [
{
title: "Hello World",
author: {
name: "John Doe"
}
},{
title: "Why am I still up at midnight writing this post?",
author: {
name: "John Doe"
}
}
]
}
}
}
Note: This example was slightly simplified. A real production GraphQL server would use batching and caching to reduce the number of requests to the backend and avoid making redundant ones — like fetching the same author twice. But that’s a topic for another post!
Conclusion
As you can see, once you dive into it GraphQL is pretty easy to understand! I think that’s pretty remarkable when you take into account how easy it makes things like joins, filtering, argument validation, documentation, which are all hard problems to solve in traditional RESTful APIs.
Of course, there’s a lot more to GraphQL than what I wrote here, but that’s a topic for future posts!
If this got you interested in trying GraphQL for yourself, you should check out our GraphQL server tutorial, or read about using GraphQL on the client together with React + Redux.
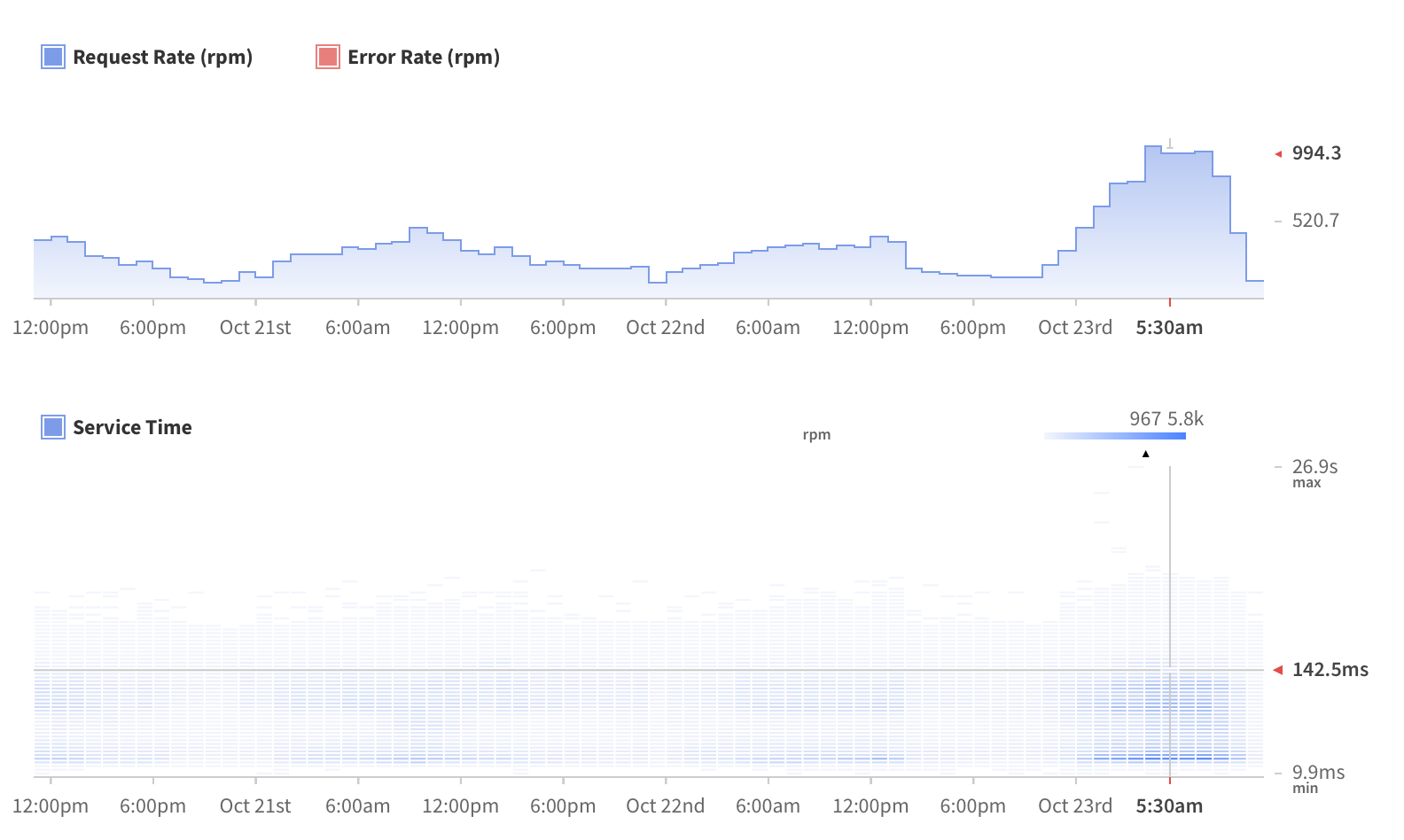
2018 Update: Understanding GraphQL execution with Apollo Engine
In the time since Jonas wrote this post, we’ve also built a service, called Apollo Engine, that helps developers understand and monitor what happens in their GraphQL server by providing:
If you’re interested in seeing the execution of your GraphQL queries in real life, you can sign in and instrument your server here. If you’re interested in support running a highly performant, modern application with GraphQL, we can help! Let us know.